| Cascade DataHub™ for Linux and QNX : Version 6.4 | ||
|---|---|---|
 | Chapter 2. Using the Cascade DataHub |  |
| Cascade DataHub™ for Linux and QNX : Version 6.4 | ||
|---|---|---|
| | Chapter 2. Using the Cascade DataHub | |
The Cascade DataHub allows programs to register for exceptions on point value changes. When a point changes value in the DataHub, all clients that have registered an interest in that point are notified.
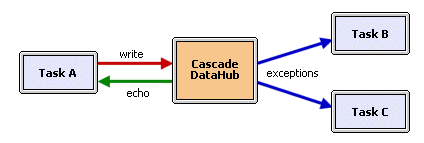
The Cascade DataHub not only allows its clients to register and receive exceptions on data points, but it also provides a special message type called an echo that is extremely important in multi-node or multi-task applications.
When the Cascade DataHub receives a new data point it immediately informs its registered clients of the new data value. The clients will receive an asynchronous exception message. In some circumstances, the client that sent the new data value to the DataHub is also registered for an exception on that point. In this case, the originator of the data change will also receive an exception indicating the data change. When there are multiple clients reading and writing the same data point one client may wish to perform an action whenever another client changes the data. Thus, it must be able to differentiate between exceptions which it has originated itself, and ones which originate from other clients. The Cascade DataHub defines an echo as an exception being returned to the originator of the value change.
In certain circumstances, the lack of differentiation between exceptions and echoes can introduce instability into both single and multi-client systems. For example, consider an application consisting of the Cascade DataHub mirroring data to a DataHub in Windows. The Windows DataHub communicates with Wonderware's InTouch program. InTouch communicates using DDE, which does not make the distinction between exceptions and echoes. A data value delivered to InTouch will always be re-emitted to the Windows DataHub, which in turn will re-emit the value to the Linux or QNX DataHub. The Linux or QNX DataHub will generate an exception back to the Windows DataHub which will pass this exception on to InTouch. InTouch will re-emit the value, and so on. A single value change will cause an infinite communication loop. There are many other instances of this kind of behavior in asynchronous systems. By introducing the echo capability into the Cascade DataHub, the cycle is broken immediately because it recognizes that it should not re-emit a data change that it originated.
The echo facility is necessary for another reason. It is not sufficient to simply not emit the echo to the originating task. If two tasks read and write a single data point to the DataHub, then the DataHub and both tasks must still agree on the most recent value. When both tasks attempt to write the point, one gets an exception and updates its current value to agree with the DataHub and the sender. If both tasks simultaneously emit different values, then the task whose message is processed first will get an exception from the first, and the first will get an exception from the second. In effect, the two tasks will swap values, and only one will agree with the DataHub. The echo message solves this dilemma by allowing the task whose message was processed second to receive its own echo, causing it to realize that it had overwritten the exception from the other task.
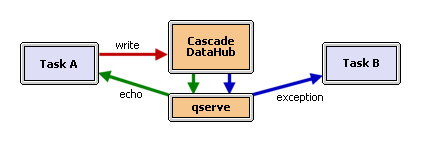
Whenever multiple tasks are communicating there is a chance for a deadlock situation. The Cascade DataHub is at the centre of many mission critical applications because it provides real-time data to its clients without the threat of being blocked on the receiving task. The Cascade DataHub never blocks on a task that is busy. It is always able to receive data from clients because it uses the Cascade QueueServer (qserve) to handle outgoing messages.
The DataHub only ever sends messages to qserve program, which is optimized so that it never enters a state where it cannot accept a message from the DataHub.
The Cascade DataHub works across any QNX 4 network. Only the qserve and nserve tasks (approx. 100 KB RAM) need to be run on the network computer; all other tasks remain on the machine with the DataHub.
All data points are created with an associated confidence factor that is delivered with every point value. Any writing program may set confidence factors. This lets you change the confidence on a point value to reflect uncertainty and can be used in more advanced control strategies to 'weight' actions and responses to alarm states.
The Cascade DataHub provides facilities for implementing security and point locking. It respects security levels and locked points, but the application programmer is responsible for how that security is allotted.
![[Important]](images/important.gif) | Changing security levels and locking points can be done through an application, or through the Cascade DataHub Viewer. For this reason, it is important to either restrict access to the Cascade DataHub Viewer, or to modify its source code to restrict access to its security features. |
Generally speaking, the Cascade DataHub assigns every task a security level, expressed as an integer ranging from 0 (the default) to 32,767. Every DataHub point also has a security level, within the same range. If a task security level is greater than or equal to a point security level, then that task has full access to the point. It can register it, read it, lock it, unlock it, write to it, and change its security to any level up to and including the task's own level. On the other hand, if a task security level is less than a point security level, that task can read the point and register it, but nothing else.
![[Note]](images/note.gif) | The point locking feature is useful for debugging, as it allows you to prevent a function from writing to a point or group of points at the points themselves, rather than altering code. |
Because the Cascade DataHub is RAM resident and requires no pre-configuration, the size of the DataHub is only limited by the available system resources.
Most of the CPU time used by the demo is consumed updating the screens. The Cascade DataHub, by itself, has a throughput of about 2500 points/sec on a Pentium 133. This number is based on using single-point messages rather than using efficient packing techniques, which would increase throughput. Also, bear in mind that a DataHub message includes transmission through the asynchronous queue server.
The lookup of points is done in logarithmic time (i.e. the time does not grow linearly with the number of points in system).
| |  | |
| 2.6. Viewing Data |  | Chapter 3. Data Transmission |
Copyright © 1995-2010 by Cogent Real-Time Systems, Inc. All rights reserved.