| Cascade Historian™ : Version 6.4 | ||
|---|---|---|
 | Chapter 1. Introduction |  |
| Cascade Historian™ : Version 6.4 | ||
|---|---|---|
| | Chapter 1. Introduction | |
Table of Contents
The Cascade Historian is an event-driven data storage program used to maintain persistent time-sequence data sets derived from process data. In addition to providing storage, it also offers a historical query facility suitable for generating graphs and tabular output for export to other analysis programs.
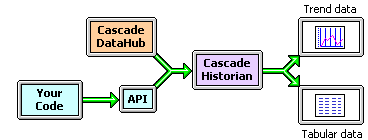
The data storage mechanism within the Cascade Historian will maintain any number of simultaneous time histories, one for each configured process point. The data for each point is maintained in one or more files, allowing for removal of stale data or off-line archival of old data. These files are either numbered in increasing numerical order, or dated. When using dated files, the Cascade Historian automatically begins logging to a new file at midnight.
The Cascade Historian records data by event. If no data change event occurs for a point, no data is written to disk. This saves disk space when the process point is idle, and captures even very short-duration events when the point is changing. This is both more efficient and more accurate than a sampling historian. It is possible to place both time and value deadbands on each point to reduce storage for points whose values are constantly changing by insignificant amounts. The Cascade Historian will not reorder out-of-sequence data.
Data is stored on disk in fixed-length binary records to minimize disk space, with a time resolution of nanoseconds. These files can be easily read by any custom program, as well as by the Cascade Historian.
Any process may request data from the Cascade Historian. It maintains a configurable in-memory cache for each point being recorded so that queries of recent data will not require disk access. If the request cannot be satisfied from the in-memory cache, then the disk files related to the point will be consulted for the data to satisfy the request. The requests can take one of the following forms:
Raw Data simply returns all recorded events for the data point, reported vs. time.
Periodic Data performs linear interpolation on the data to produce a data set at an even time interval. This produces the same result that a sampling historian would produce.
Relative Interpolation performs interpolation of one data point against another to produce a Y vs. X data set. Interpolation is performed on Y to produce (X,Y) pairs at the times of known values of X.
Periodic Relative Interpolation performs interpolation of one data point against another to produce a Y vs. X data set. Interpolation is performed on both X and Y to produce (X,Y) pairs at an even time interval.
The Cascade Historian has been built to allow quick addition of other forms of historical query.
| |  | |
| Cascade Historian |  | 1.2. System Requirements |
Copyright © 1995-2010 by Cogent Real-Time Systems, Inc. All rights reserved.