| Cascade Historian™ : Version 6.4 | ||
|---|---|---|
 | Chapter 3. System Overview |  |
| Cascade Historian™ : Version 6.4 | ||
|---|---|---|
| | Chapter 3. System Overview | |
Table of Contents
The Cascade Historian functions provide the following activities:
Data collection: Data may arrive from supporting objects such as the Cascade DataHub or from various external sources such as user's programs.
Disk storage: The Cascade Historian organizes data in the files and files on the disk.
Services:
Time-based synchronization. The system provides a local time stamp to the data and stores the data according to that stamp in order to guarantee that the data is time-sequenced.
Interpolation. The system collects only the values which a variable assumes at the sampling periods. However it provides the intermediate values and the intermediate times upon request.
Time-based analysis. The system supplies the first derivative, average value over a time range, and value at a given time.
Query support. The system provides the time at which a variable has a specific value, values of one variable at available values of another, and also values of both the first variable at available values of the second and the second variable at available values of the first.
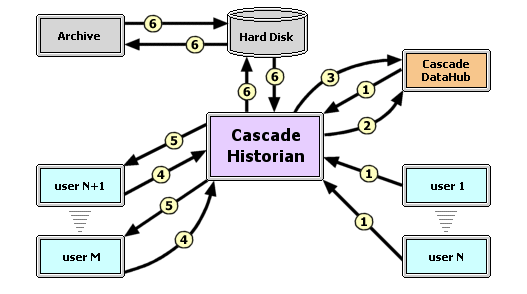
The basic interactions of the Cascade Historian with the external objects are shown in the figure below. The flows of data shown are:
| (1) data collection | (4) request for service |
| (2) control flow (e.g., command to register a point) | (5) service rendered |
| (3) results of time-based analysis | (6) data reading and/or writing |
Users 1 through N represent sources of data; users N+1 through M represent clients. The Cascade DataHub is a supporting object to the Cascade Historian. The Cascade Historian sends commands to the Cascade DataHub, for example, to register for a point. The Cascade DataHub then provides data on the points for which the Cascade Historian has registered. (The Cascade Historian may send the results of queries or time-based analysis to the Cascade DataHub to make these results accessible to the rest of the system.) The Cascade Historian exchanges information with the disk, such as by reading or writing files. Data from the disk may be transferred to an archive, as shown in the figure. Although the Cascade Historian itself does not provide this facility, it will detect and manage the files available to it.
The primary source of data for the Cascade Historian is the Cascade DataHub, which provides data through the process of registration. Data may also arrive directly from the users (various tasks). The Cascade Historian is able to read data from the disk to fulfill the requirement on data analysis and on supporting trend plots and other operator interface displays.
In this system data is modeled in several ways.
Points are named values that you can interact with just by using their names. A point can be any variable whose history is worth collecting.
As a point arrives to the Cascade Historian, the system provides it with a time stamp, making it a part of the history data structure. These histories are stored in a file according to the information that the user provides: the directory on the disk, and the filename. This information becomes a part of the history.
The Cascade Historian stores the points as a time series, using either the timestamp associated with a point (from the application sourcing the point), or if no time is available, timestamping the point as it arrives. The data stored on file is this original (unprocessed) time series. Queries process one or more time series, to provide, for example, the interpolated values of a variable at an array of times {t1,...,tn}.
To accommodate newly arriving data, the Cascade Historian allocates two buffers in memory : one is called current and the other is called previous. As new data arrives it is placed in the current buffer until that buffer is full. Then all the data is written to the disk, and also copied to the previous buffer. Thus, after writing to the disk, the most recent data is still available from the previous buffer in memory, rather than from the disk only. This is done to maximize performance during queries, so that queries on "recent" data can avoid accessing the disk. Both the current and previous buffers are dynamically re-sizable to optimize the tradeoff between memory usage and performance.
The system provides long-term data storage on disk. A single history is stored per file which, with its monotonically-increasing time and fixed format, provides quick and efficient access to data. The directory location and filename associated with a history must be explicitly configured by the user. The file name consists of three parts:
A base name, which is a string of characters.
An optional file identifier.
The extension portion of the filename.
The file identifier, if used, specifies one of the following modes of file naming:
A unique, increasing integer number that is appended to the base name. Every time a file is (re)associated with a history the number is automatically incremented by 1. The result is a set of distinct files which segment the data based on an external decision or event.
For example, a new file will be created when the historian re-starts. Or the historian could be forced to begin writing to a new file when a certain file size is reached, a production run completed, or on a daily or weekly basis. The number of (zero-padded) digits in the identifier is specified by the corresponding parameter.
The date in the format YYYYMMDD. This effectively provides every file with a time stamp which indicates the beginning of data collection in that file.
Whichever mode is chosen, the use of this file identifier provides a sensible mechanism for managing the problem of archiving older data files for an on-going history. If only a single filename is provided for a history, then it becomes impossible to segment the history data (the file continues to grow as long as data of interest exists for this variable), or to combine data from multiple files into a single continuous history for analysis. The Cascade Historian automatically detects all the available files for a history (using the same file identifier mode) and transparently combines the files into a single time-series for the purpose of analysis.
The extension can be any string of characters to be appended to the filename. Common conventions include .dat or .hist, but no default extension is necessary or defined.
For example, to store data on a variable called temperature, if a user specifies the directory to be /usr/data, the base name temperature_, the identifier to be 2, and the extension to be .hist, then the initial file to be stored will have the filename /usr/data/temperature_01.hist.
Each file contains only history data, organized as (time, value) pairs of binary doubles (with a total of 16 bytes per datum). This facilitates direct reading and analysis of the data by other applications.
Internally, the historian maintains much more information for each history in order to transparently and efficiently manage the file or set of files associated with the history. This includes the total number of points and the times associated with the first (earliest) and last (latest) values for each file. Whenever a history is associated with a filename (thereby specifying a file or set of files), the directory is scanned and analysed to reconstruct this information.
The Cascade Historian may need to access data from the disk from time to time in order to provide services. The amount of data to be analyzed may exceed the amount of memory available at that moment, which makes copying to memory undesirable. To optimize memory usage, the system estimates the size of the buffer that is to hold the answer to a query.
For the type of query where the Cascade Historian is asked to provide (interpolate) values of variable r2 at available values of r1 over the time range (t1 t2), the size of the answer buffer can be evaluated precisely. If T is the sampling period for r1 , then the number of records N in the answer is the integer part of the ratio (t2 - t1)/T. Each record has a fixed length of L bytes which is known to the Historical Database. Thus, the buffer to hold the answer is N * L bytes long.
For the type of query where the times at which a variable takes a specific value are required, the size of the response cannot be determined. In this case dynamic allocation of memory is required.
The nature of the queries supported by the system lets you analyze the data step by step. Namely, the Cascade Historian performs a binary search to find the starting point for the analysis, writes small (depending on the query) portions of data into the memory, processes them, and writes the result into the answer buffer.
The Cascade Historian allows for long-term archiving. Information from the disk can be transferred to an off-line archive system by some external mechanism. The Cascade Historian detects the removal of a file from the disk to an archive. It keeps track of the files on the disk and knows what information is no longer available.
All data is supplied with a time stamp, giving a basis for the sequencing of individual variables and the association in time of different variables. Time is used as the independent variable, that is, all variables store the time along with the value of the variable. The Cascade Historian uses the time stamp of the originating data supplied from the Cascade DataHub. If the time stamp in the Cascade DataHub is 0, the Cascade Historian will generate a time stamp at the time of receipt of the data. In either case, if the resulting time stamp is earlier than the last known time for the same variable, then the Cascade Historian will generate a time stamp using the formula (last_known_time_stamp + 1 microsecond).
The system provides linear and quadratic (second order) interpolation of data. Quadratic interpolation is implemented using Simpson's method.
There is no strict rule imposed to choose the type of interpolation. The choice depends on the expected "shape" of the data trend and the deviation of data from the trend. If data varies a lot in frequency and amplitude, then the quadratic type would be preferable. Otherwise the linear type would be appropriate.
One way to determine the type of suitable interpolation is to evaluate the first derivatives at the sampling points. If the first derivatives significantly differ in the absolute values and signs, then quadratic interpolation should be used.
In cases where the interpolation becomes CPU-intensive, sampling is provided.
Time-based analysis is supported by supplying, for example, the first and the second derivative for a given variable, the value at a point in time, and the average of values over the range of time.
The Cascade Historian supports the following types of queries:
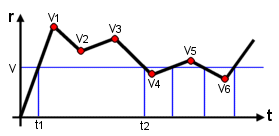
Query the time at which the dependent variable r (e.g. reflectance) has a specific value v, {r, v} (see the figure below). The Cascade Historian generates an array of times {t1 ,... tn}. The value stored (such as v1 v2 v3 ...vn) may not correspond to exactly v, so the times are estimated based on a first-order interpolation.
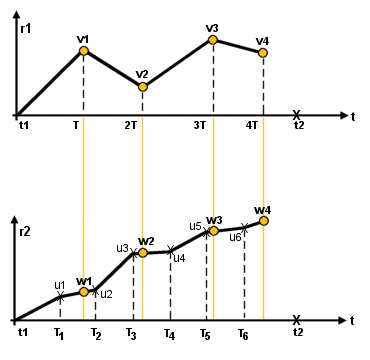
Query for the values of a pair of variables , say r1 and r2 , over a range of time from t1 to t2 . { r1 r2 t1 t2 mode}, resulting in an array of tuples {v1 w1 ,...} (see the figure below). Here the mode specifies the type of selection of the tuples:
Interpolate r2 at available values of r1.
Interpolate r1 at available values of r2.
Interpolate r1 and r2 as required to generate tuples at all known r1 and r2 values.
As an example, mode (1) is shown in the figure. Here T and T1 are the sampling periods for the variables r1 and r2 respectively, {v1, v2,...} and {u1, u2,...} are the arrays of stored values for r1 and r2, and {w1, w2,...} is the array of the desired (interpolated) values for r2. (Values {u1, u2,...} are marked as crosses on the graph, values {v1, v2,...} and {w1, w2,...} as colored dots.). For the variable r2 we partition the t-axis with the sampling period T of the variable r1. Then we interpolate r2 at the new partition and obtain the required array {w1, w2,...}.
Mode (2) works similarly to mode (1), with r1 and r2 interchanged. In this case the partition of t-axis for r2 predetermines the points of interpolation for r1.
Mode (3) is a union of modes (1) and (2). We first refine the partition T1 of t-axis for r2 by adding the points of partition T. ( In the example shown in the figure the refined partition is {T1, T, 2T1, 3T1, 2T, 4T1, 5T1, 3T,...}). Then we interpolate r2 just as we did in mode (1), in order to obtain array {w1, w2,...}. The next step is to repeat the procedure of mode (2) and to produce the approximate values {y1, y2,...} for r1 at the points { T1, 2T1, 3T1, ...}. Finally we combine all four arrays of known values for r1 and r2 in one array of tuples. The order of tuples corresponds to the order of time in the refined partition of t-axis: {y1 u1, v1 w1,...}.
| |  | |
| 2.4. Error Handling |  | 3.2. Information Flow |
Copyright © 1995-2010 by Cogent Real-Time Systems, Inc. All rights reserved.